ResNet (Residual Network) の実装

画像認識タスクにおいて、高い予測性能をもつ ResNet。ImageNetのSOTAランキングでも、EfficientNetと並び、応用モデルが上位にランクインしています。ライブラリ等を用いれば事前学習済のResNetは簡単に読み込めますが、モデルの構造をきちんと実装しようとすると、どうなるでしょうか?
今回は、このResNetをPyTorchを用いて実装していきたいと思います。
様々な応用モデルが存在するResNetですが、もともとは2015年に Deep Residual Learning for Image Recognition という論文で提案された手法になります。大きな特長は、skip connection あるいは residual connection と呼ばれる、層を飛び越えた結合を持つことです。
下図がモデルの概要図です(図は元論文より引用)。
引用元:Deep Residual Learning for Image Recognition
- 【画像をクリックすると拡大します】

図の右に飛び出ている結合が skip connection になります。
また、この図に “34-layer residual” とあるように、ResNetは層の深さが異なる複数のモデルがあり、論文内では18層、34層、50層、101層、152層のモデル構造が提案されています。
それぞれの構造は下表の通りです(表は元論文より引用)。
引用元:Deep Residual Learning for Image Recognition
- 【画像をクリックすると拡大します】
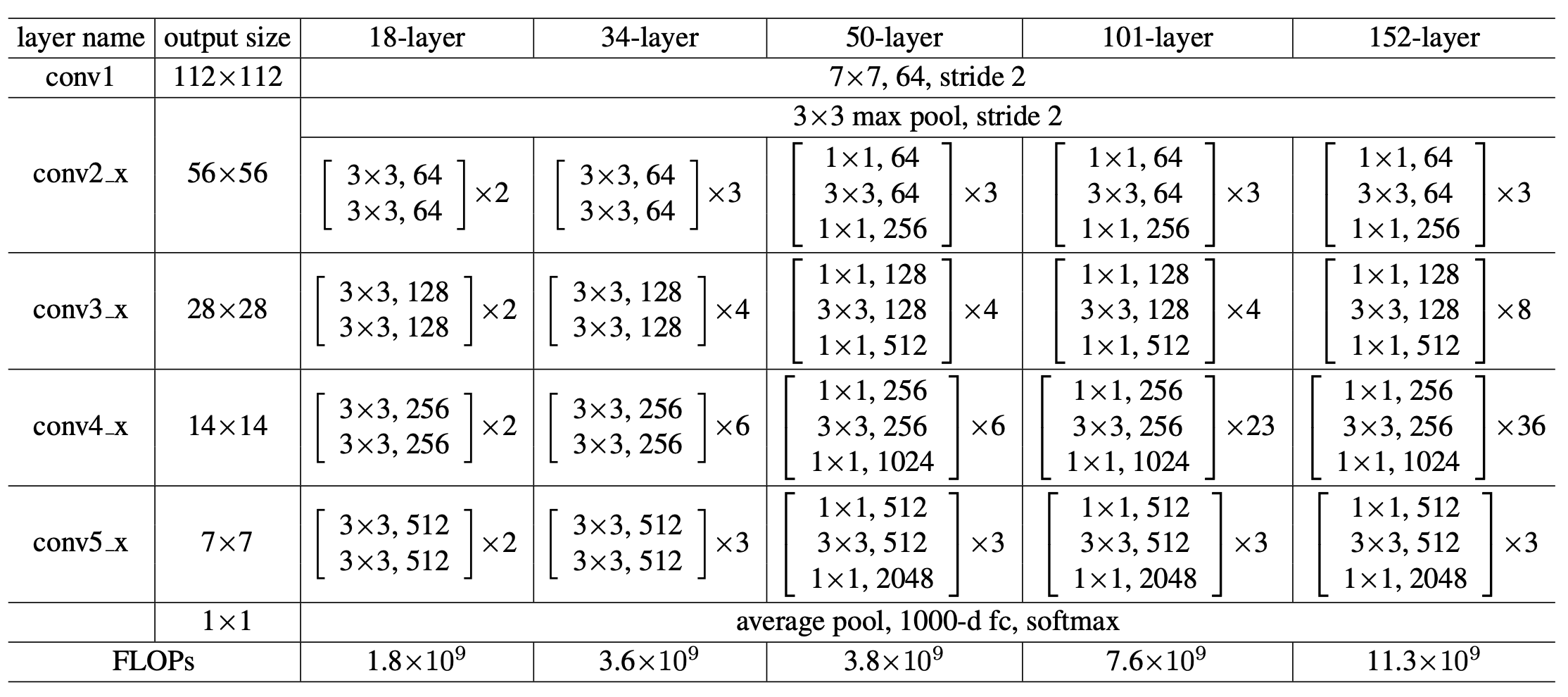
今回は、このうち50層のモデル (ResNet50) を実装してみましょう。
上表にある [ ] で囲まれた部分は building blocks と呼ばれるモジュールで、グラフィカル表現にしたものが下図になります(図は元論文より引用)。
引用元:Deep Residual Learning for Image Recognition
- 【画像をクリックすると拡大します】
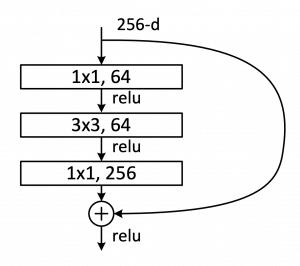
1×1 あるいは 3×3 のカーネルサイズを持つ畳み込み層を積み重ねた構造で、チャネル数は出力層に近づくにつれ大きくなっていきます。
まずは、このブロック構造を実装してみましょう。下記がコードになります。ResNet50(以降のモデル)では、skip connection を行うために最後にチャネル数を調整しなくてはならない場合がある(すなわち、ブロックの入力のチャネル数を、出力のチャネル数に合わせる必要がある)ので、これを shortcut として実装しています。
中身はシンプルで、1×1 の畳み込みを差し込むことによるチャネル数の調整になります。
import pytorch.nn as nn
class Block(nn.Module):
def __init__(self, channel_in, channel_out):
super().__init__()
channel = channel_out // 4
# 1x1 の畳み込み
self.conv1 = nn.Conv2d(channel_in, channel,
kernel_size=(1, 1))
self.bn1 = nn.BatchNorm2d(channel)
self.relu1 = nn.ReLU()
# 3x3 の畳み込み
self.conv2 = nn.Conv2d(channel, channel,
kernel_size=(3, 3),
padding=1)
self.bn2 = nn.BatchNorm2d(channel)
self.relu2 = nn.ReLU()
# 1x1 の畳み込み
self.conv3 = nn.Conv2d(channel, channel_out,
kernel_size=(1, 1),
padding=0)
self.bn3 = nn.BatchNorm2d(channel_out)
# skip connection用のチャネル数調整
self.shortcut = self._shortcut(channel_in, channel_out)
self.relu3 = nn.ReLU()
def forward(self, x):
h = self.conv1(x)
h = self.bn1(h)
h = self.relu1(h)
h = self.conv2(h)
h = self.bn2(h)
h = self.relu2(h)
h = self.conv3(h)
h = self.bn3(h)
shortcut = self.shortcut(x)
y = self.relu3(h + shortcut) # skip connection
return y
def _shortcut(self, channel_in, channel_out):
if channel_in != channel_out:
return self._projection(channel_in, channel_out)
else:
return lambda x: x
def _projection(self, channel_in, channel_out):
return nn.Conv2d(channel_in, channel_out,
kernel_size=(1, 1),
padding=0)
この Block クラスを利用して、ResNet50 クラスの実装をしてみましょう。ResNet50はブロック構造が4つ並んでいるだけとも言えるので、コード自体は非常にシンプルにまとまります。
下記が実装の内容です(ただし、実装中に出てくる GlobalAvgPool2d に関しては後述します)。
import torch
import torch.nn as nn
class ResNet50(nn.Module):
def __init__(self, output_dim):
super().__init__()
self.conv1 = nn.Conv2d(1, 64,
kernel_size=(7, 7),
stride=(2, 2),
padding=3)
self.bn1 = nn.BatchNorm2d(64)
self.relu1 = nn.ReLU()
self.pool1 = nn.MaxPool2d(kernel_size=(3, 3),
stride=(2, 2),
padding=1)
# Block 1
self.block0 = self._building_block(256, channel_in=64)
self.block1 = nn.ModuleList([
self._building_block(256) for _ in range(2)
])
self.conv2 = nn.Conv2d(256, 512,
kernel_size=(1, 1),
stride=(2, 2))
# Block 2
self.block2 = nn.ModuleList([
self._building_block(512) for _ in range(4)
])
self.conv3 = nn.Conv2d(512, 1024,
kernel_size=(1, 1),
stride=(2, 2))
# Block 3
self.block3 = nn.ModuleList([
self._building_block(1024) for _ in range(6)
])
self.conv4 = nn.Conv2d(1024, 2048,
kernel_size=(1, 1),
stride=(2, 2))
# Block 4
self.block4 = nn.ModuleList([
self._building_block(2048) for _ in range(3)
])
self.avg_pool = GlobalAvgPool2d() # TODO: GlobalAvgPool2d
self.fc = nn.Linear(2048, 1000)
self.out = nn.Linear(1000, output_dim)
def forward(self, x):
h = self.conv1(x)
h = self.bn1(h)
h = self.relu1(h)
h = self.pool1(h)
h = self.block0(h)
for block in self.block1:
h = block(h)
h = self.conv2(h)
for block in self.block2:
h = block(h)
h = self.conv3(h)
for block in self.block3:
h = block(h)
h = self.conv4(h)
for block in self.block4:
h = block(h)
h = self.avg_pool(h)
h = self.fc(h)
h = torch.relu(h)
h = self.out(h)
y = torch.log_softmax(h, dim=-1)
return y
def _building_block(self,
channel_out,
channel_in=None):
if channel_in is None:
channel_in = channel_out
return Block(channel_in, channel_out)
ResNet50では、最後の全結合層に接続する際に、global average poolingを行います。これを GlobalAvgPool2d クラスで実装してみましょう。
下記がコードになります。
import torch
import torch.nn as nn
import torch.nn.functional as F
class GlobalAvgPool2d(nn.Module):
def __init__(self,
device='cpu'):
super().__init__()
def forward(self, x):
return F.avg_pool2d(x, kernel_size=x.size()[2:]).view(-1, x.size(1))
以上で必要なレイヤーがすべて実装できました。
それでは、Fashion MNIST を対象として、実際に学習・評価をしてみましょう。全体の実装は次の通りです(学習に時間がかかりますので、エポック数は 5 にしています)。
import os
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optimizers
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
import torchvision
import torchvision.transforms as transforms
from sklearn.metrics import accuracy_score
class ResNet50(nn.Module):
# 省略
class Block(nn.Module):
# 省略
class GlobalAvgPool2d(nn.Module):
# 省略
if __name__ == '__main__':
np.random.seed(1234)
torch.manual_seed(1234)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
'''
データの読み込み
'''
root = os.path.join(os.path.dirname(__file__),
'..', 'data', 'fashion_mnist')
transform = transforms.Compose([transforms.ToTensor()])
mnist_train = \
torchvision.datasets.FashionMNIST(root=root,
download=True,
train=True,
transform=transform)
mnist_test = \
torchvision.datasets.FashionMNIST(root=root,
download=True,
train=False,
transform=transform)
train_dataloader = DataLoader(mnist_train,
batch_size=100,
shuffle=True)
test_dataloader = DataLoader(mnist_test,
batch_size=100,
shuffle=False)
'''
モデルの構築
'''
model = ResNet50(10).to(device)
'''
モデルの学習・評価
'''
def compute_loss(label, pred):
return criterion(pred, label)
def train_step(x, t):
model.train()
preds = model(x)
loss = compute_loss(t, preds)
optimizer.zero_grad()
loss.backward()
optimizer.step()
return loss, preds
def test_step(x, t):
model.eval()
preds = model(x)
loss = compute_loss(t, preds)
return loss, preds
criterion = nn.NLLLoss()
optimizer = optimizers.Adam(model.parameters(), weight_decay=0.01)
epochs = 5
for epoch in range(epochs):
train_loss = 0.
test_loss = 0.
test_acc = 0.
for (x, t) in train_dataloader:
x, t = x.to(device), t.to(device)
loss, _ = train_step(x, t)
train_loss += loss.item()
train_loss /= len(train_dataloader)
for (x, t) in test_dataloader:
x, t = x.to(device), t.to(device)
loss, preds = test_step(x, t)
test_loss += loss.item()
test_acc += \
accuracy_score(t.tolist(), preds.argmax(dim=-1).tolist())
test_loss /= len(test_dataloader)
test_acc /= len(test_dataloader)
print('Epoch: {}, Valid Cost: {:.3f}, Valid Acc: {:.3f}'.format(
epoch+1,
test_loss,
test_acc
))
以上を実行すると、次のような結果が得られ、きちんとResNetで学習ができていることが確認できます。
Epoch: 1, Valid Cost: 0.469, Valid Acc: 0.839 Epoch: 2, Valid Cost: 0.451, Valid Acc: 0.850 Epoch: 3, Valid Cost: 0.418, Valid Acc: 0.858 Epoch: 4, Valid Cost: 0.448, Valid Acc: 0.850 Epoch: 5, Valid Cost: 0.365, Valid Acc: 0.877
今回は、CNNのモデルのひとつであるResNetの実装を紹介しました。Skip connection は実装もシンプルであるにもかかわらず、高い予測性能につながりますので、しっかり内容について理解しておきましょう!
また、このような学習モデルを扱う職種の方向けの案件紹介サービスとして、BIGDATA NAVI(ビッグデータナビ)があります。ビッグデータ関連の求人サイトでは業界最大級の案件数を誇り、機械学習・AIなどの先端案件が豊富であることが魅力です。
ITエンジニアやプログラマー、データサイエンティスト、コンサルタント・PM・PMOといったIT系人材は一度登録して案件紹介を受けてみるとよいでしょう。


東京大学 招聘講師、日本ディープラーニング協会 有識者会員。2018年にForbes 30 Under 30 Asia 2018 に選出。著書に『詳解ディープラーニング』、監訳書に『PythonとKeras によるディープラーニング』(マイナビ出版刊)等がある。


