機械学習における転移学習・ドメイン適応

機械学習・ディープラーニングを今後さらに発展させる技術として「転移学習」が注目されています。転移学習はすでに学習されたモデルを応用して、他の領域へと適応するための技術です。
機械学習の仕事を探している場合は「AI分野の専門エージェント」への登録もおすすめです。
今回は、転移学習とドメイン適応を中心に、実用例、将来性についても紹介します。
目次
機械学習とは?

転移学習について触れる前に、そもそも機械学習とは何であるかについて理解しておく必要があります。簡単に言ってしまえば、機械学習とは、コンピューターに自動でデータを学習させ、課題を解決することを目標とする学術分野といえるでしょう。従来の手法では、何か複雑なタスク(人の顔を見分ける、文章から感情を推測する、など)をコンピューターを使って達成するには、人間が明示的にプログラミングによって指示を与えてあげる必要がありました。つまり、if-elseといった条件文やループなどを多用して、細部に渡るまで人間がプログラムを作り込む必要があったのです。
それに対して機械学習とは、そういった煩雑なプロセスを最小化するために考え出された手法で、人間がデータを与えるだけで、後はコンピューターが与えられたデータから自動で学習するという仕組みになっています。ここでいう学習とは、統計的手法やニューラルネットワークなどを用いてデータをその特徴ごとに分析・分類することを指し、機械学習の中でも特にニューラルネットワークの層が深くなったものをディープラーニング(深層学習)と呼んでいます。
機械学習における欠点
大量のデータが必要

一見すると万能で欠点がないようにも思える機械学習という手法ですが、一つの致命的な欠点があります。それは、与えるデータ量が十分でないと学習不足となり、有用な性能が得られない、ということです。そもそも機械学習やディープラーニングといった理論は、最近になって提唱され始めたものではなく、1940年代から既にアラン・チューリングなどの数学者によって予想・研究されていました。しかし、当時はコンピューターの性能も悪く、十分なデータ量も確保できなかったため、今ほどの注目を浴びる研究成果は得られませんでした。
この話からも推測できるように、機械学習においてデータ量というものは核となるものであり、それは現在においても変わっていません。実際、優れた精度を誇る機械学習モデルは、大規模なデータを元にトレーニングされたものばかりです。つまり、機械学習がその真価を発揮できるのは、課題としている分野におけるデータ量が十分にある場合に限ると言えます。
訓練データは偏りのないものでなければならない
それでは、ある一定のデータ量が確保できればそれで十分かというと、必ずしもそうではありません。機械学習モデルを訓練する際に与えるデータ(Training Data)が偏っていると、そのモデルの汎用性が下がり、結果的に性能も下がってしまいます。このように、モデルがある特定のドメイン(データの集まり)に偏ってしまうことを過学習(Overfitting)と呼び、これを避けるために現在も様々な手法が研究されています。
データが偏るということに関して、簡単な例を挙げてみましょう。血圧などの基礎的なデータから人の健康状態を推測すること(健康か否か)を目標とする機械学習モデルを訓練するとします。しかし、若年層のデータが少ないため、十分なデータ量が確保できている高齢層のデータを使ってモデルを訓練することになりました。その結果、高齢層に対してはある程度正確な分類ができるものの、若年層に対しては誤った結果(健康であるのに、病気と診断されるなど)となってしまうようなモデルが出来上がってしまいました。
ここでの問題点は何かというと、モデルの一般化する能力が低い、というところにあります。つまり、若年層と高齢層における健康的な数値(血圧など)の取りうる幅が異なるにも関わらず、高齢層のデータを多く訓練させたために、モデルが正しいとする基準も高齢層のデータに寄ってしまっているのです。このように、機械学習モデルに与えるデータは、量だけでなく、その質も高くなければならないのです。
転移学習とドメイン適応

では、ある分野において十分なデータ量が得られない場合、もしくはデータが偏ってしまう場合は、どのようにしてその問題を解決すべきなのでしょうか?現在、その解決策の一つとして、転移学習(Transfer Learning)とドメイン適応(Domain Adaptation)という手法が注目されています。
転移学習(Transfer Learning)
転移学習の定義
転移学習とは、機械学習手法の一つで、あるタスクに対して訓練されたモデルをそれと関連したタスクに応用する手法のことです。既に学習された知識(Knowledge)を他の課題へ転移する(Transfer)というイメージからKnowledge Transferとも呼ばれています。
関連したタスクと書きましたが、タスクとは- どういった種類のデータ(ドメイン)に対する
- どういった種類のタスク(e.g. 分類や回帰)であるか
という2つの要素に分けることができるため、転移学習とは以下の3つのパターンに分類することができます。
- 異なるドメイン、異なるタスクに関するもの
- 異なるドメイン、同じタスクに関するもの
- 同じドメイン、異なるタスクに関するもの
しかし、ここでいうドメインが異なるとは具体的にはどのようなことを指すでしょうか?基本的に2つのドメインを比較した際に、以下の3つの内のどれか1つでも異なっていればその2つのドメインは異なっていると判断することができます。
- Input Space (Description Space) 入力するデータの種類、入力値の取りうる値の範囲
- Output Space (Label Space) 出力するデータの種類、出力値の取りうる値の範囲
- PDF (Probability Density Function, Probability Distributions) 確率分布のこと。例えば、サイコロを1回振って1- 6の目が出る確率はそれぞれ1/6であるので、確率分布は全ての目に対して平等に1/6となります。
したがって転移学習とは、タスクが異なるにせよ同じであるにせよ、偏りのないデータ量が豊富にあるドメイン(Source Domain)からデータ量が確保できない異なるドメイン(Target Domain)への知識のマッピングであるということができ、上記で説明した機械学習の欠点を解決しようとしていることがわかります。例えば、Word2vecによる単語の分散表現を、文章やツイートの感情分析に活用するというのも、転移学習の応用であるといえるでしょう。
転移学習を行うためのアプローチ
上で述べたように、転移学習には大きく分けて3種類あり、それに加えて教師あり(ラベル付き)・教師なし(ラベルなし)とでアプローチが異なってくるため、かなり幅広い分野であることがわかります。しかし、基本的に目指していることはどの場合でも同じであり、少ないデータ量から少ない訓練時間でモデルの精度を上げることに他なりません。
転移学習は、ディープラーニング(つまりニューラルネットワークの層が深く、多くのデータ量を必要とするモデル)を用いて行われることが多く、下位層はそのままに、上位層のみを訓練し直すというアプローチを取るのが一般的です。これは、ニューラルネットワーク(CNNなど)の低レイヤーはより一般的なデータの特徴(Features)を、高レイヤーはよりタスク特有の特徴を含む傾向にあるからであり、これによってこれまでタスク毎に何日とかかっていたモデルの訓練時間を大幅に削減することが出来るようになりました。
ドメイン適応(Domain Adaptation)
ドメイン適応とは、転移学習の一種であり、ドメインは違うものの上でいう3番(Probability Distributions)のみが違うケースを指します。つまり、Source DomainとTarget Domainの観測データは同じであるが、確率分布が違う場合に有効な手法です。
ドメイン適応は、ターゲットとするデータにラベルが付いているか否かで、教師ありドメイン適応(Supervised Domain Adaptation)、半教師ありドメイン適応(Semi-supervised Domain Adaptation)、教師なしドメイン適応(Unsupervised Domain Adaptation)とに分けることができますが、この中でも一番難易度が高いのはターゲットに正解ラベルが付いていない教師なしドメイン適応です。しかし、最近の研究では従来の誤差逆伝播法の途中にGradient Reversal Layerと呼ばれる層を組み込むことによって、教師なしであってもドメイン適応によりモデルの精度を上げることができるようになりました。
引用元:Y Ganin and V Lempitsky, Unsupervised Domain Adaptation by Backpropagation, ICML 2015
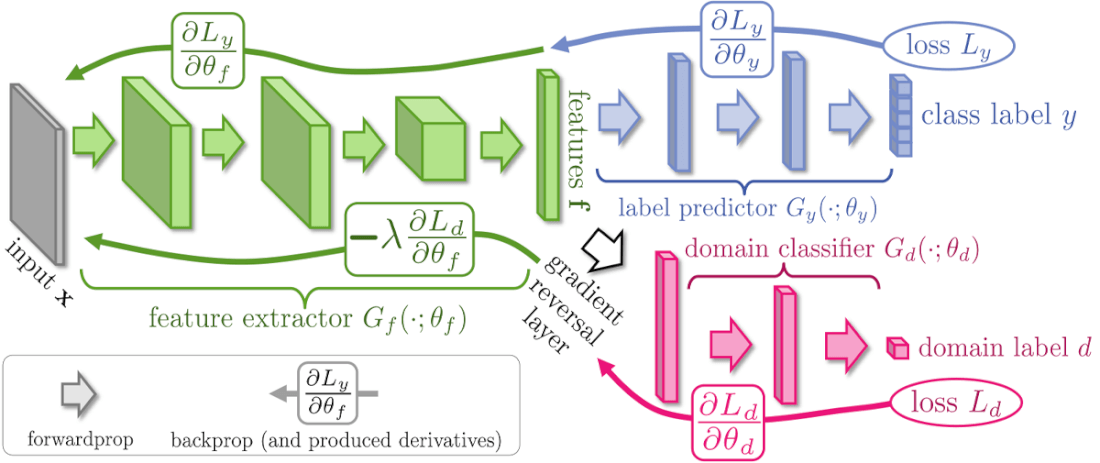
上記の図はそのモデルの構造を表したものです。簡潔に説明すると、ドメイン適応とディープラーニングを用いて、ドメイン間で共通の特徴とドメイン固有のものとに分け、異なるドメイン間で同じモデルを使いまわせるようにしたものであると言えます。上の図からもわかるように、このモデルではニューラルネットワークを3つのパート ― 与えられたデータから特徴を抽出するFeature Extractor、ラベルを予測するLabel Predictor、ドメインを認識するDomain Classifier ― に分け、Label Predictorの損失関数が最小化され、Domain Classifierの損失関数が最大化されるようにネットワークを学習させています。通常、ニューラルネットワークの学習では損失関数を最小化するように、つまりエラーが最も少なくなるように学習させることを大前提としていますが、このモデルではGradient Reversal Layerにおいて、学習の内部で計算されている勾配に負の定数を掛けることで損失関数を最大化すること、つまりドメイン間で共通の特徴を探し出すことを実現しています。
転移学習の実用例・BERT
転移学習は自然言語処理の分野においてもその威力を発揮しつつあります。2018年にGoogleが発表したBERTというモデルは、数多くの自然言語処理のタスクで過去最高精度を叩き出したことで一躍有名になりました。このモデルの特徴は、すでに大量のデータを用いてトレーニング済みの汎用モデルでありながら、異なるタスクで高いパフォーマンスを発揮するというその汎用性の高さにあります。つまり、ニューラルネットワークの上位層のみを訓練する(Fine-tuning)だけでよく、モデルを一から訓練する必要がないということです。これは、自然言語処理の分野ではデータ量が確保し辛いという従来の課題に対する解決策であり、異なるドメインで同等のパフォーマンスを発揮することを目標とする転移学習の一例であると捉えることができるでしょう。
転移学習とこれから
転移学習は、モデルを一から訓練する必要を無くし、開発者の時間的なロスを最小化することを目標としています。また、現在は一部企業によるデータの寡占化のような構造が続いているため、大規模なデータにアクセスができる企業や組織が、自らの持つデータ量を活かした研究を積極的に進めていくことが理想的であるといえるでしょう。転移学習は、そういった個人や企業のアクセスできるデータ量の格差を縮めるという点においても、これから注目されていく分野であることに違いありません。具体的なタスクに関するAIが世界中で開発され続け、飽和状態になりつつある現在、次に目指すべきものは汎用的な処理能力を持ったAI の開発ではないでしょうか?そういったAIを束ねる汎用的AIの開発の中心には、転移学習というコンセプトがあることは想像に難くないでしょう。
ITエンジニア向けの案件紹介サービスとして、BIGDATA NAVI(ビッグデータナビ)があります。ビッグデータ関連の求人サイトでは業界最大級の案件数を誇り、機械学習・AIなどの先端案件が豊富であることが魅力です。
ITエンジニアやプログラマー、データサイエンティスト、コンサルタント・PM・PMOといったIT系人材は一度登録して案件紹介を受けてみるとよいでしょう。


AIを仕事にするためのキャリアノウハウ、機械学習・AIに関するTopics、フリーランス向けお役立ち情報を投稿します。


